I don't love the single responsibility principle
May 06, 2014 by Marco Cecconi
May 06, 2014 by Marco Cecconi

courtesy of wikipedia
Did you ever happen to disagree with a colleague on the single responsibility principle and its application? Let's try to understand why that could be the case.
I once worked with a colleague, whom we shall call Stan, who had a very different understanding of the single responsibility principle than I had. During code reviews, his feedback would often be that my classes "tried to do too much" and broke the single responsibility principle. My feedback to his patches was often the opposite, that his classed did too little and lacked cohesion.
How can we explain this disagreement? Let's assume that we both know the SRP and try to apply it at the best of our abilities: I can only see two alternatives.
The first possibility is that the classes are actually the wrong size. People are wrong all the time: maybe I was wrong and he was right or vice versa. While this sometimes happens, I would expect any reasonably competent developer who is aware of the SRP to only make this kind of mistakes in exceptional cases and not in a fundamental manner. Also, for a class to have the wrong size, there must be an objective measurement of the size, and this should eliminate pointless arguments.
The other possibility would be that different programmers have a different understanding of the principle or how it is presented. In turn, they can't agree on what constitutes the appropriate size and thus can't reach an agreement.
This is intriguing, so let's dig a bit further: Uncle Bob's Single Responsibility Principle states that
A class should have one, and only one, reason to change.
and
In the context of the Single Responsibility Principle (SRP) we define a responsibility to be “a reason for change.” If you can think of more than one motive for changing a class, then that class has more than one responsibility.
-- Bob Martin
Interesting. So the "size" of the class, for example, is not a factor in complying or breaking the SRP. Furthermore, the word "responsibility" is bizarrely defined as a "reason to change". The key here is there must be a single reason to change.
Fundamentally, the SRP principle is therefore a class sizing principle. Its purpose is to help developers group functionality into appropriate classes.
Unfortunately, there are a few big problems with the SRP.
There's no explanation of what constitutes a "reason" or a "change". Is bug fixing a change? It clearly is -- the code changes, there is a patch, duh. Is a bug a valid reason to change? Either bug fixing is a good reason, and it becomes the "one and only" reason to change, or bug fixing is not a good reason and the principle must allow for changes without good reason.
In both cases, the definition doesn't seem precise enough to be practically useful, but from the context of Robert Martin's explanation, it seems that he would not consider a bug fix a change.
My objection, though, is not limited to bug fixing, but also performance improvements, refactoring… Aren't all these valid reasons to change? There's a wrong assumption in the definition, that we can easily, spontaneously and unequivocally agree on what constitutes a reason, a change and ultimately a responsibility. This is absolutely not the case in real life.
In fact, Uncle Bob gets even more confusing. In an example of applying the SRP he states:
Should these two responsibilities be separated? That depends upon how the application is changing.
Wait, what? This really makes no sense: when one writes code, there are only real, present requirements. The future is pretty irrelevant, so asking to design based on future requirements is uncanny.
Even more confusingly the principle is then corrected with a caveat (which he calls "corollary"):
There is a corrolary [sic] here. An axis of change is only an axis of change if the changes actually occurr [sic]. It is not wise to apply the SRP, or any other principle for that matter, if there is no symptom.
In other words: classes can only have reasons to change when there are new requirements. But by then, all the bad stuff that's supposed to happen if we violate SRP already happened! What's the advantage of a principle that only applies retroactively? I find this idea is not justified by any real world case.
Even if we identify one and only Reason To Change™, there is no concept of a good or bad reason in the principle: can we concentrate a whole search engine in a single class simply because we can flatly state that its responsibility is "to find the documents most relevant to a query"? Can we separate any class until each has a single method, which is its unique responsibility?
All these cases seem to be allowed by the principle. Or they seem to be disallowed -- depending on how you read it.
Clearly there's a definition missing, and the principle does not work unless we all agree on what constitute a valid responsibility.
The principle is arbitrary in itself. What makes one and only Reason To Change™ always, unequivocally better than two Reasons To Change™? The number one sounds great, but I'm a strong advocate of simple things and sometimes a class with more reasons to change is the simplest thing.
I agree that we mustn't do mega-classes that try to do too many different things, but why should a class have one single Reason To Change™? I flatly disagree with the statement. It's not supported by any fact. I could say "three" reasons and be just as arbitrary.
Let me give an example from Uncle Bob's own chapter:
Figure 8-4 shows a common violation of the SRP. The Employee class contains business rules and persistence control. These two responsibilities should almost never be mixed. Business rules tend to change frequently, and though persistence may not change as frequently, it changes for completely different reasons. Binding business rules to the persistence subsystem is asking for trouble.
Stating that "binding business rules to persistence is asking for trouble" is flatly wrong. Au contraire, It's the simplest thing to do, and in most cases any other solution is just adding complexity without justification. Not all applications are big enterprise-y behemoths that benefit from Perfect 100% Decoupling™ and it should also be noted that separating persistence is trivial as it doesn't imply a signature change and that in a huge number of practical cases a business entity will be the only realistic client of its persistence, thus hardly justifying decoupling at all.
(I am purposefully ignoring unit testing here. Designing for testability gives you testable code, but not necessarily readable or maintainable code -- that's a discussion for another blog post.)
Furthermore, there is no reason to separate "business" logic from "persistence" logic, in the general case. The large majority of Employee classes that people need to write are likely to only contain fields and maybe some validation -- in addition to persistence. I would argue that validation and persistence do belong together because they do normally change together. Sure, there may be classes where persistence is better handled elsewhere, and cases where business logic is better handled elsewhere. Separate them in that case, but only when necessary.
The example that Robert uses in his own chapter seems to be cherry picking of a badly design class to "prove" a point. But a hand-crafted example is a straw man, not a proof. Here it is:
The Rectangle class has two methods shown. One draws the rectangle on the screen, the other computes the area of the rectangle.
The class is not in itself badly designed if it lives in a single-layer application. If the application has UI and Business layers, though, it has a problem because it's not clear where it should be sitting. Without any reference to the SRP it's obvious that this class needs fixing and in the single-layer application scenario, the SRP introduces unnecessary and arbitrary complexity.
There's no balance. All the examples I see are one-way towards simply creating a million single method classes. There's no way in which we are supposed to merge two classes into one.
So, whilst I agree completely on the premise of not make ginormous classes, I think this principle is not at all helpful in either illustrating the concept or even identifying unequivocally problematic cases so they can be corrected. In the same way, anemic micro-classes that do little are a very complicated way of organizing a code base.
With a definition of "reason" which is very narrow, then a class is probably better off handling more than one "responsibility", and more than one reason to change. We don't want all classes to be wrappers around single methods, that may be great in functional programming, but it is very bad object oriented programming.
The obvious result of a bad principle is that it fails the primary purpose of guiding people to write better code. Instead, not only it makes them write bad code, it also makes people waste breath and goodwill on trivialities when they should probably focus on other problems in their code.
This is exactly what happened between me and Stan: the principle was not clear enough to agree on its application.
Consequently, the SRP a principle only in name: it rephrases "don't write a monolith" without giving any unequivocal or valid way of identifying the correct design.
A good, valid principle must be clear and fundamentally objective. It should be a way of sorting solutions, or to compare solutions.
This is my alternative no-nonsense class sizing principle:
The purpose of classes is to organize code as to minimize complexity. Therefore, classes should be:
- small enough to lower coupling, but
- large enough to maximize cohesion.
By default, choose to group by functionality.
It's not a clear-cut principle: it does not tell you how to code. It is purposefully not prescriptive. Coding is hard and principles should not take the place of thinking.
Furthermore, applying this principle is an exercise in balance: make classes too small and you loose cohesion. Make them too big and you gain coupling.
On the other hand, I believe this principle is clear enough to raise the level of discourse and entice developers to have constructive arguments instead of religious ones.
It is also quite objective in the sense that coupling and cohesion are well defined concepts.
If client code need to know class B in order to use class A, then A and B are said to be coupled. This is bad because it complicates change, but also because it makes code harder to write, as the purpose of writing a class is making client code unaware of the details by hiding (encapsulating) unnecessary complexity.
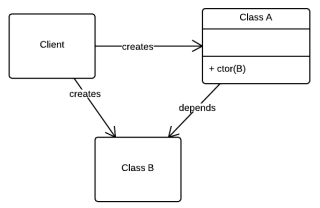
Fig 1. — A coupled system
// client code
// in order to create A I need to know B
// A and B are coupled
var bInstance = new B();
var aInstance = new A( bInstance );
Cohesion is similar to coupling but it happens within a single class and does not interfere with client code. It is a measure of the internal co-dependencies of the methods of a class. Classes with high cohesion are impossible to subdivide further without exposing internal state. Merging classes which already have common dependencies will raise cohesion. Proper encapsulation also increases cohesion because it forces clients to manipulate the internal state of a class only via its methods, which in turn exhibit high cohesion because of that.
A nice example of coupling and cohesion is the following: a class C has two independent groups of methods does not have maximal cohesion.
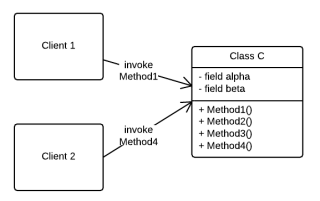
Fig 2. — Class C does not have maximal cohesion, but has low coupling
Splitting it in two parts creates two classes A and B with better cohesion. If we leave the original class C as a client of A and B for backwards compatibility, we introduce coupling (because creating C to use A also unnecessarily creates B so it's more coupled than creating A). Furthermore class C will still have low cohesion.
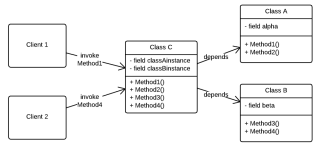
Fig 3. — Classes A and B have maximal cohesion, but C has high coupling and low cohesion
In order to resolve the problems with class C, the implementation of C should be inlined, which means that the clients of C will use A and B separately.
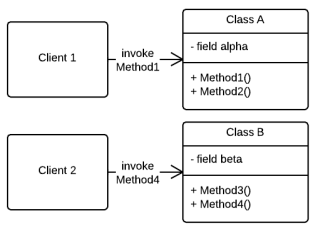
Fig 4. — Inlining class C maximizes cohesion and minimizes coupling
Another example is when A and B are always used together in the same order. Then it's likely that either B depends on A (or vice versa), thus the solution has unnecessary coupling, or that the correct encapsulation is a set of higher level operations involving A and B, which will probably have higher cohesion.
I really tried to understand the SRP, and to like it. I really tried. But I can't agree with it, and that's why I decided to publish this. In the next few weeks I will be looking at more SOLID principles and see if they stand up to reason.
Hi, I'm Marco Cecconi. I am the founder of Positron Lans, developer, hacker, blogger, conference lecturer. Bio: ex Stack Overflow core team, ex Toptal, ex BaxEnergy.
Read moreMarch 31, 2026 by Marco Cecconi
Positron Flux is a new a delivery excellence workbench
Read moreFebruary 20, 2026 by Marco Cecconi
Last night I decided to dedicate some time to my old [z80 emulator](https://sklivvz.com/posts/z80). I've squashed a few bugs and ported it to .NET 10. Then I added a ULA emulator.
Read moreFebruary 08, 2026 by Marco Cecconi
Compile-time translations via source generators, ICU MessageFormat + CLDR plurals, PO file workflows, no per-request allocations.
Read moreDecember 27, 2024 by Marco Cecconi
TDD can’t guarantee zero-defects. Let us debunk this software development myth.
Read moreMarch 12, 2023 by Marco Cecconi
Stack Overflow could benefit from adopting a using conversational AI to provide specific answers
Read moreWhat began, in Boole’s words, with an investigation “concerning the nature and constitution of the human mind,” could result in the creation of new minds—artificial minds—that might someday match or even exceed our own.
Read more…
{kind=link}